BLOG
(EG only) Learning to classify anything with a hybrid model

Modern deep learning systems can accurately classify data with accuracy exceeding human capabilities in many different tasks. However, these systems are trained to maximise performance on a fixed dataset and therefore if, after deployed in the field, they encounter a new kind of data they have never seen, they can catastrophically fail.

One way to fix this problem is to reconsider the way machine learning models are trained in the first place. Instead of teaching them a fixed mapping of data to labels, we can teach them to learn to quickly associate new pieces of data with their corresponding information. To achieve this, we train the system in an episodic manner: every new round it needs to learn a novel association between data and labels. The faster it can reach high accuracy and the fewer examples it needs to correctly classify, the more reward it gains.
For example, in the case of image classification we can train the system by taking an image dataset and reshuffling the class labels on each episode. We can then show it image-label pairs and test its accuracy after seeing a few examples.
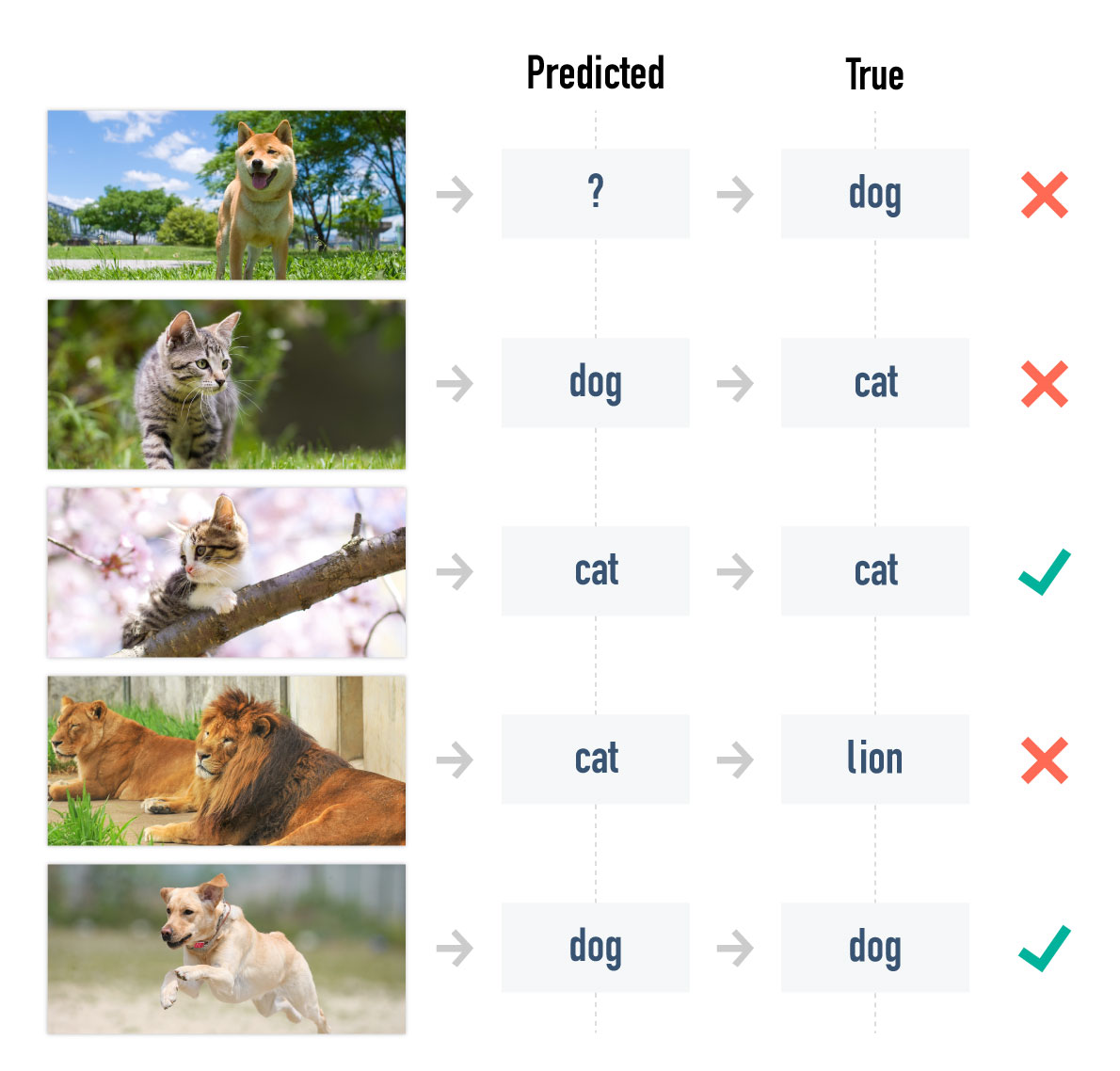
Existing algorithms to perform this kind of task presuppose they are shown the context (a certain number of reference image/label pairs) at the beginning of the episode, and then only refer to that context until the end. This setup has two crucial limitations: the algorithm cannot improve its accuracy as it sees more data, and the context might be too big in some cases.
In a paper recently accepted to the ICLR 2019 conference we demonstrate a new algorithm to use only as much memory for its context as necessary to correctly perform the task. The proposed algorithm has the following novel features:
・Learns to only store the data-label example pairs that it really needs to perform well on the task by using a principle derived from information theory.
・Uses an efficient memory accessing mechanism which allows it to recall thousands of seen classes in its context without compromising on performance.
・Can combine information present in multiple memory pieces to generate novel answers to problems.
The algorithm
While the algorithm could be applied to a number of different tasks here we will mostly focus on image classification. We consider that every episode is a sequential classification task: at every time step we are shown an image and are asked its correct label. We are then shown the correct label after making our guess.
Our proposed architecture, called APL (adaptive posterior learning), consists of an encoder which generates a representation for the given image, a memory store where we can look up previous representations and their labels, an inference module which generates the model’s guess, and a memory controller which decides what to write based on the final answer.
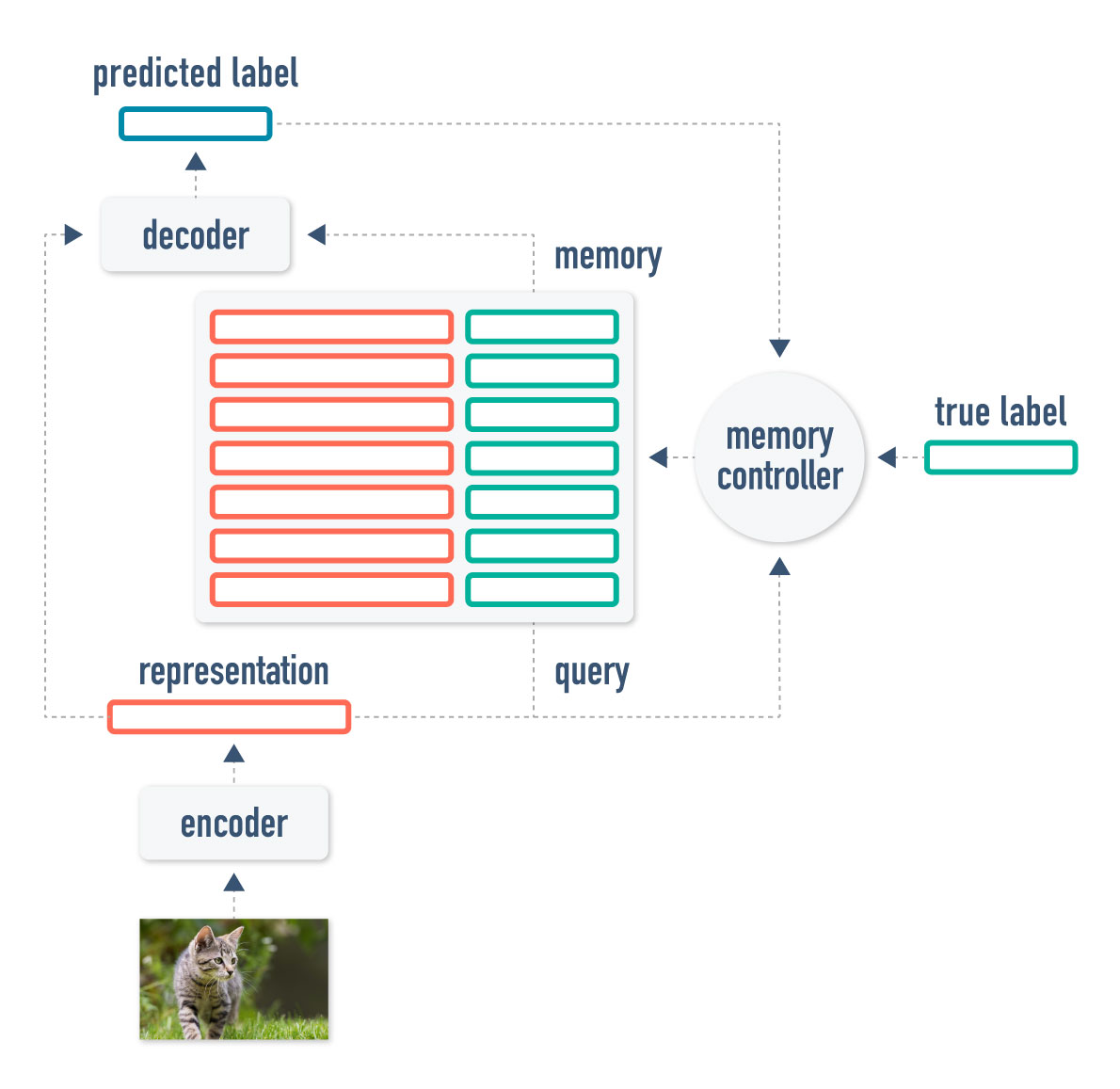
Let’s look at each element in detail.
・Encoder
The encoder is a function which takes in arbitrary data and converts it to a lower dimensional representation. In all our experiments we choose a convolutional network architecture for the encoder.
・Memory store
The external memory module is a database containing the stored experiences. Each of the columns corresponds to one of the attributes of the data. In the case of classification, for example, we store two columns: the representation produced by the encoder and the true label. Each of the rows contains the information for one example. The memory module is queried by finding the k-nearest neighbors between the query’s representation and the representations stored in the database. The full row data for each of the neighbors is returned for later use.
When the network is untrained, the representations might not be informative enough to retrieve the correct information from memory. As the network trains, the encoder learns to map representations of similar classes together, which means the retrieval process starts to work correctly. Meta-learning algorithms in general are slower to train because of this issue, but the algorithm they learn in the end is much more robust than that of a fixed classifier.
・Decoder
This module takes as input the query representation as well as all the data from the neighbors found in the external memory; and outputs a vector with probabilities for each possible class. Architecture-wise, we tested a number of possibilities: a relational feed-forward module with self attention, a relational working memory core and an LSTM.
・Memory controller
We use a simple memory controller which tries to minimize the amount of data points written to memory. Let us define surprise as the log of the probability of a certain label -log(Pr(class)). Intuitively, this means that the higher the probability our model assigns to the true class, the less surprised it will be.
This suggests a way of storing the minimal amount of data points in memory which supports maximal classification accuracy. If a data point is ‘surprising’, it should be stored in memory; otherwise it can be safely discarded as the model can already classify it correctly.
How should the memory controller decide whether a point is ‘surprising’? In this work we choose the simplest possible controller: if the surprise is greater than some predefined value, then that data should be stored in memory. We make this value proportional to -log(N) where N is the number of classes under classification (this is the surprise value of a model which attributes equal probability to all classes).
Conveniently, in the case of classification problems the commonly used cross-entropy loss reduces to our measure of surprise directly, and we therefore use the prediction loss as an input to the memory controller directly.
Results
We tested our method on a number of image classification tasks. One of those tasks is the omniglot classification task, which consists of matching characters from a number of foreign alphabets to the correct character label. In every episode we shuffle the character labels.
We show that using this algorithm leads to performance matching other state of the art algorithms while using less memory in the case of a 5 and 20-way classification task. Moreover, using our algorithm we can scale to a 1000-way classification task and still obtain good performance, something which is impossible using other methods (refer to the paper for full results).
We’ve also applied this method to an analogy task, where the information in multiple memories needs to be combined to produce the right answer. In this case, we show the model a number and a symbol with a corresponding result. Once the network sees one number + symbol combination, it should be able to generalize by figuring out how much the symbol adds or subtracts from the number and applying that to the new number.
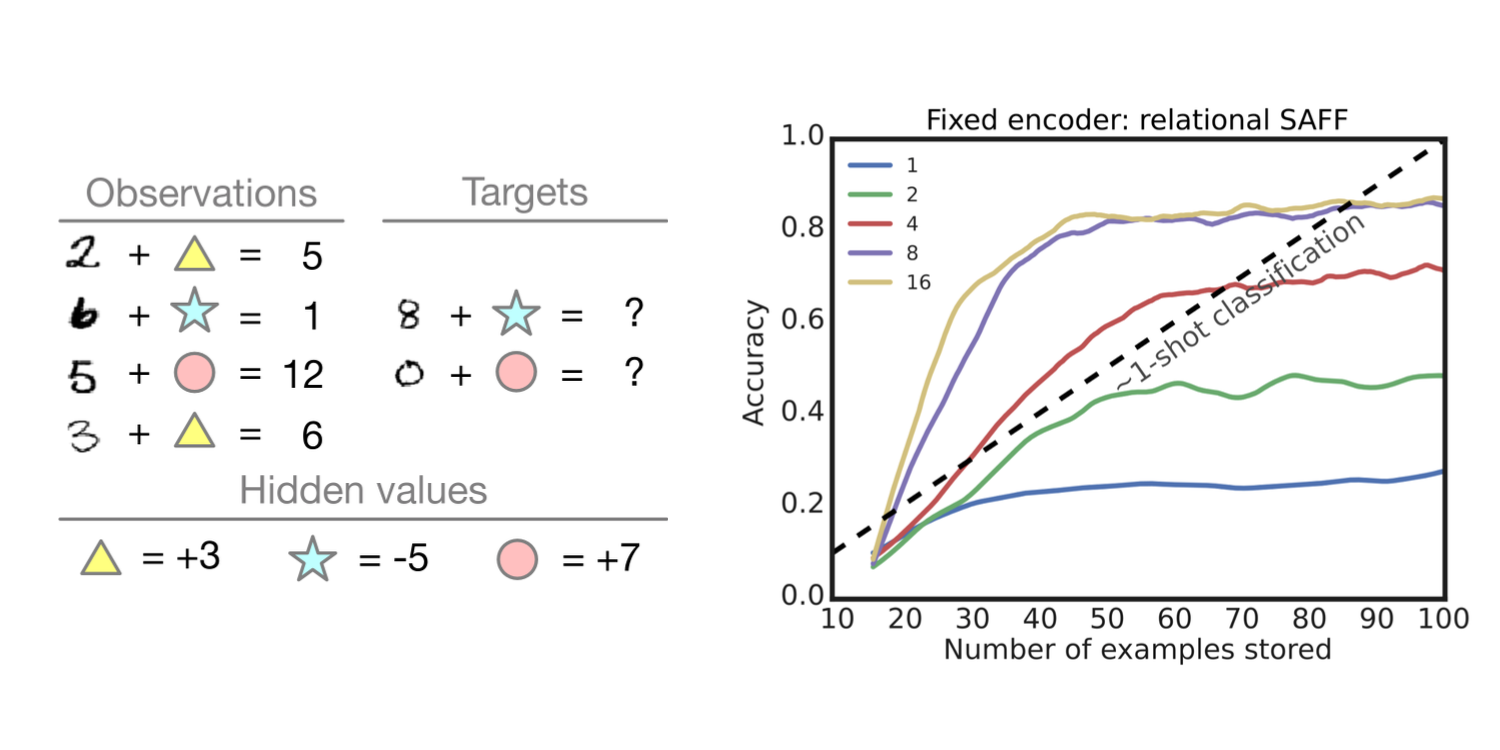
In the paper we show that the model can correctly generalize from a single number + symbol combination to answer all following queries correctly without ever having seen those combinations before. In the figure below, the dashed line represents perfect accuracy for an algorithm that can do 1-shot classification (i.e. it needs to see one example of each combination). We can see that when it can access information from 8 or 16 neighbours, our algorithm is able to exceed 1-shot classification performance and achieve good accuracy with much fewer examples.
Paper on arXiv: https://arxiv.org/abs/1902.02527
OSS code: https://github.com/cogentlabs/apl